Further Study
What Next?¶
So far, we have mostly discussed supervised learning. In supervised learning, the model is trained on a labeled dataset. This means that each input comes with the correct answer. The goal is to learn a rule that works not only on the training examples, but also on new, unseen examples.
Pros:
High accuracy when enough labeled data is available.
Predictable performance and easier to evaluate.
Well-supported with mature libraries.
Cons:
Requires large, clean labeled datasets, which can be expensive or time-consuming to produce.
May overfit if there is not enough data or if the model is too complex.
Unsupervised models¶
Unsupervised learning works with unlabeled data. Here, the model is not told the correct answer. Instead, it tries to discover hidden patterns, groups, or useful representations inside the data.
For example, if we give a model many customer profiles without labels, it may discover groups of customers with similar purchasing habits. In physics, unsupervised methods can also be useful for anomaly detection, dimensionality reduction, compression, and representation learning.
One important example is an autoencoder. An autoencoder tries to compress the input into a smaller hidden representation and then reconstruct the original input from that representation. If the reconstruction works well, the hidden representation has captured something useful about the data.
Example: Autoencoder
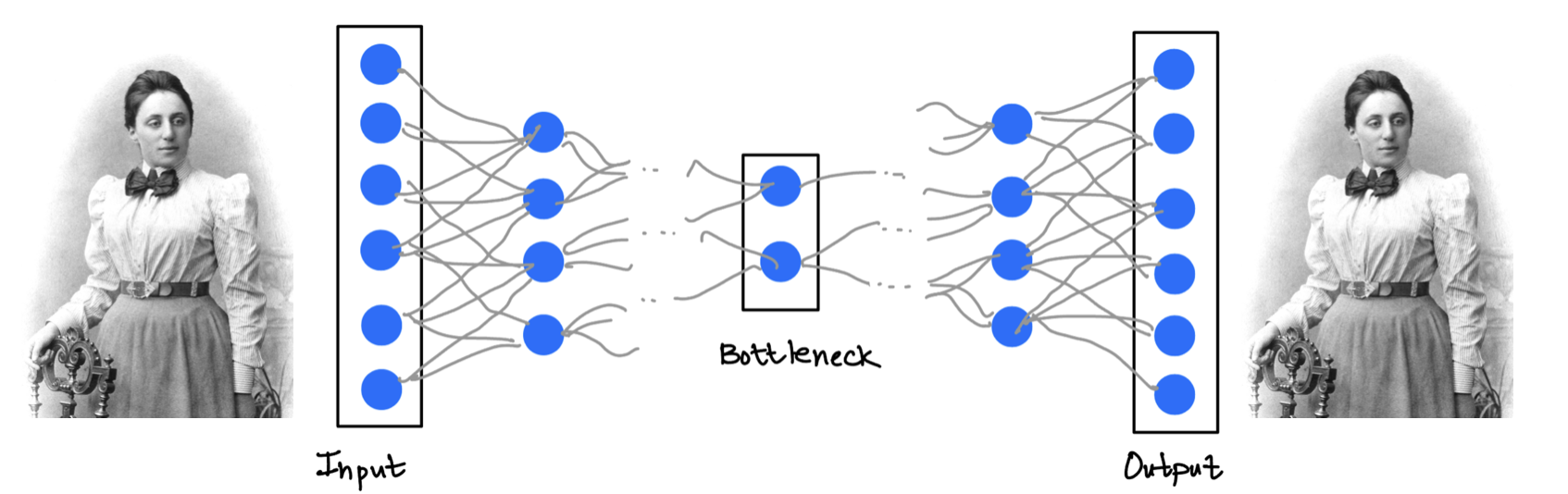
Pros:
Works without labeled data.
Helps with data exploration, dimensionality reduction, compression, and pattern discovery.
Cons:
Harder to evaluate, because there is no obvious ground truth label.
May discover patterns that are mathematically real but physically or practically unimportant.
Often requires care in interpreting what the model has learned.
Reinforcement Learning¶
Reinforcement learning is different from both supervised and unsupervised learning. Here, the model is usually called an agent. The agent interacts with an environment, takes actions, and receives rewards or penalties.
The goal is not simply to predict a label. The goal is to learn a good strategy.
A typical reinforcement learning loop looks like this:
For example, a robot learning to walk, a program learning to play chess, or an algorithm learning how to control a system can all be thought of in this framework.
Pros:
Very useful for sequential decision-making and control tasks.
Learns from interaction rather than from a fixed labeled dataset.
Can discover strategies that are difficult to write down by hand.
Cons:
Often slow and computationally expensive.
May require a lot of exploration or simulation before learning effectively.
Rewards must be designed carefully, otherwise the agent may learn the wrong behavior.